
Illuminating the Danger of MLOps Without Data Lineage
The rise of MLOps has transformed machine‑learning deployment from isolated experiments into full production systems. As businesses scale, they build complex data pipelines, deploy models in cloud environments, and demand continuous performance. Meanwhile regulatory scrutiny, compliance pressure, and ethical responsibilities are growing. In that context, tools for data lineage as tracking data from source to output, are often proposed as the backbone of trustworthy ML systems. But adopting data lineage tools in MLOps is controversial: are they indispensable for accountability, or do they add cumbersome operational overhead that slows innovation? This article frames that tension as a critical choice: transparency and trust at the cost of complexity, or speed and simplicity with hidden risks.
Why MLOps Needs Transparency? The Case for Data Lineage Tools
The Rise of Regulatory Demands in MLOps
Data governance is no longer optional for organizations leveraging machine learning. As data volume grows, organizations must ensure data quality, traceability, and compliance with standards from internal audits to external regulations. Data lineage provides a systematic record of where data originates, how it transforms, and where it flows, enabling robust governance over ML pipelines. techtarget.com+2ibm.com+2
Without transparent lineage, it’s nearly impossible to prove that a model’s output stems from clean, approved data, a fatal flaw when audits or regulatory reviews occur. Modern data‑governance frameworks rely on lineage to provide visibility, traceability, and accountability across data lifecycles. ibm.com+2ibm.com+2
Operational Benefits of Visibility in Machine Learning Workflows
Beyond compliance, data lineage delivers practical operational value in MLOps workflows. It gives teams the ability to debug, reproduce, and audit any stage of the data pipeline from raw input to final model inference. neptune.ai+2ibm.com+2
- Accelerated root cause analysis
- Guaranteed experiment reproducibility
- Efficient data and model reuse
- Confidence for auditors and regulators
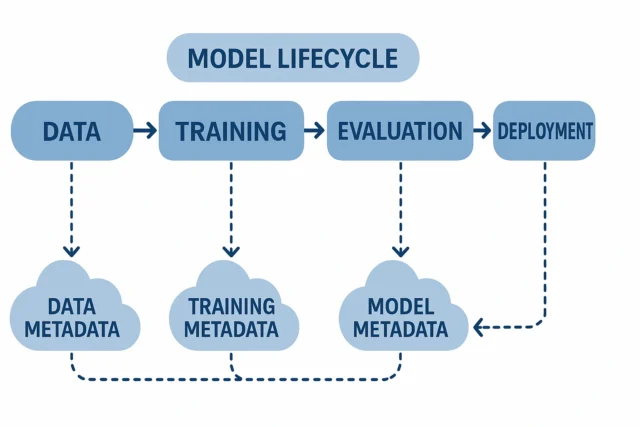
The Deployment Model of Cloud Computing Shapes the MLOps Landscape
Public vs Private Cloud in MLOps Integration
The architecture chosen for ML workloads as public cloud, private cloud, or hybrid, fundamentally influences how lineage tools integrate and perform. In a public‑cloud environment, many managed data and ML services already offer built‑in metadata logging, versioning, and data‑flow tracking. This environment makes data lineage easier to implement and more comprehensive, because lineage tools can tap into existing infrastructure rather than requiring manual setup.
However, public cloud often comes with vendor lock‑in, cross‑service tracing complexity, and potential compliance/legal issues when data crosses regions or services. Tracking data lineage across multiple managed services can be challenging; and migrations or audits become more complicated if data flows span different providers.
Hybrid Architectures and the Cost of Observability
| Deployment Model | Ease of Lineage Integration | Observability Challenges |
| Public Cloud | High (native support) | Cross-service tracing, vendor lock-in |
| Private Cloud | Medium (custom setup) | High maintenance burden |
| Hybrid/Multi-Cloud | Low to Medium | Data fragmentation, inconsistent metadata |
the choice of deployment model shapes the cost-benefit calculus for data lineage in MLOps. The more distributed or hybrid the infrastructure, the more essential but also more expensive; good lineage becomes.
Automation vs Complexity: Are We Losing the Plot in MLOps?
The Promise of Seamless Automation in MLOps
At its core, MLOps promises automation like continuous integration, continuous delivery (CI/CD), automated training, monitoring, and deployment transforming ML into scalable, repeatable, production-grade systems. Wikipedia+2agilelab.it+2
Automation streamlines workflows, reduces manual errors, and enables rapid iteration. When working with volatile data, shifting requirements, or dynamic models, automated pipelines are the only way to sustain ML operations at scale.
When Automation Obscures Operational Clarity
Introducing lineage tools can restore transparency, yet they also bring their own complexity: metadata storage, orchestration overhead, tracking across disparate systems, increased maintenance. In poorly managed setups, lineage becomes noise: large volumes of metadata, slower data processing, and added overhead that may outweigh the clarity gained.
The Data Pipeline Dilemma: Traceability or Bottleneck?
Multi‑Stage Pipelines and the Burden of Metadata
Modern ML workflows often comprise multi‑stage data pipelines: ingestion, cleaning, transformation, feature engineering, augmentation, storage, model training, inference, monitoring, and feedback loops. Each stage can involve multiple systems and transformations. Data lineage captures this entire journey, which at scale means a deluge of metadata. neptune.ai+2Actian+2
This comprehensive tracking delivers traceability and accountability. Teams can answer: where did this data come from, what transformations did it undergo, and how did the output get generated? That’s essential for debugging, compliance, and governance.
When Lineage Turns Into Latency
But registering every transformation can become a bottleneck. Constant metadata logging may slow ingestion or transformation processes. Storing redundant versions of data, tracking every minor change, or logging enormous datasets can consume storage and compute resources. In fast‑moving environments, where data arrives continuously and models must retrain quickly, this overhead can degrade performance, slow down pipelines, and increase costs.
- Latency from synchronous metadata logging
- Storage bloat from versioned datasets
- Duplication of transformed datasets
- Delays in pipeline execution due to tracking overhead
Over‑instrumentation risks defeating the purpose: the lineage becomes so heavy that it hurts agility rather than enabling it.
Control Version Systems: Necessary or Just Another Silo?
Version Control as an MLOps Best Practice
Beyond tracking data flow, version control for data, models, and code is fundamental to robust MLOps. Version control enables reproducibility, collaboration, and traceability across experiments and deployments. lakeFS+2Wikipedia+2
Tools such as DVC allow data scientists and engineers to use Git-like workflows for data and model files, decoupled from code repositories, enabling snapshots, rollbacks, and experiment tracking. Wikipedia+1
Fragmentation Risks Across Code, Data, and Models
| Artifact Type | Ideal Version Control Tool | Risk of Fragmentation |
| Code | Git | Low |
| Data | DVC, LakeFS | Medium |
| Models | MLflow, Weights & Biases | High without integration |
DevOps vs DataOps vs MLOps: Who Owns What?
Role Confusion Across Engineering Disciplines
The rise of MLOps has blurred the boundaries between traditional software engineering (DevOps), data engineering (DataOps), and ML operations. Each discipline has its own tools, processes, and ownership expectations. Wikipedia+2VE3+2
DevOps focuses on code, CI/CD, deployments; DataOps handles data ingestion, pipeline quality, cleansing, governance; MLOps ties together data, models, deployment, monitoring, and lifecycle management. When lineage is introduced, who is responsible? Metadata tracking? Data provenance? Governance documentation?
Without clear ownership, data lineage becomes a political and operational burden instead of a strategic asset.
Centralizing Ownership to Reduce Overhead
Conversely, when organizations adopt a unified, cross‑functional model with shared ownership across DevOps, DataOps, and MLOps, lineage becomes an enabler, not a drag. Teams collaborate on data governance, pipeline design, and model deployment as a coherent whole. That integration reduces duplication, avoids silos, and ensures that data lineage and version control provide real value.
In such setups, lineage tools and version control blend seamlessly into the workflow; they don’t feel like “extra overhead,” but like core infrastructure.
Team Tool Overlap in MLOps Ecosystems
AI Governance and MLOps: A Marriage of Compliance and Chaos?
The Compliance Imperative for Data Lineage
Organizations increasingly face regulatory, ethical, and compliance demands around AI and data usage. Governing bodies demand transparency like where data comes from, how it’s processed, and how models make decisions. Data lineage transforms data flows into evidence auditable, traceable, defensible. ibm.com+2databahn.ai+2
In regulated industries such as finance, healthcare, public sector, failing to provide lineage can be catastrophic: compliance violations, reputational damage, legal exposure. For them, lineage isn’t optional, it is fundamental to responsible AI deployment.
The Operational Price of Meeting Governance Standards
- Need for centralized metadata repositories
- Enforcement of access control and audit logging
- Continuous policy compliance across environments
- Investment in compliance-oriented DevSecOps
MLOps Must Choose Transparency Over Simplicity Every Time
The debate between transparency and complexity in MLOps is not theoretical. As machine learning systems make real‑world decisions: affecting finance, health, security. the cost of opacity becomes unbearable. Data lineage tools are not bureaucratic overhead: they are essential infrastructure for trust, accountability, and compliance.
Yes, adding lineage introduces complexity: metadata management, infrastructure weight, slower pipelines, process overhead. But those are minor costs compared to the hidden dangers of untraceable data flows: irreproducible models, unexplainable outputs, regulatory exposure, and erosion of stakeholder trust.
Enterprises embracing MLOps must view data lineage as foundational not just optional. The burden of complexity is the price of long‑term reliability. Investing in lineage and version control is not slowing innovation but it’s safeguarding the credibility of AI-powered business.
References
- Why Data Lineage Matters for Governance – IBM
- Understanding Data Lineage for Machine Learning – Neptune.ai
- How Cloud Deployment Shapes MLOps – AWS
- Managing Model Risk and Compliance with Data Lineage – Collibra
- Explaining the MLOps Architecture – LakeFS
- Decoding the MLOps-DevOps-DataOps Triangle – Dataiku
- MLOps and the Human Touch: Enabling AI or Slowing It Down?